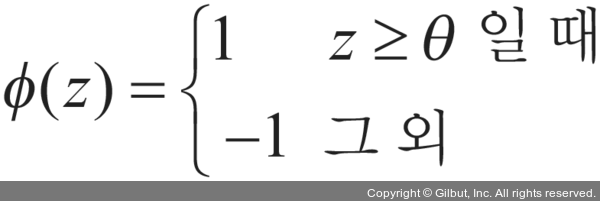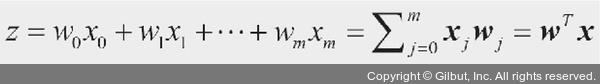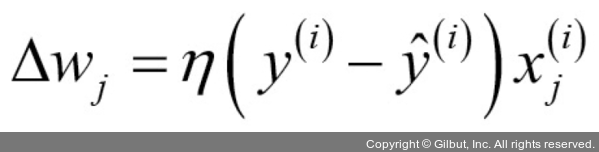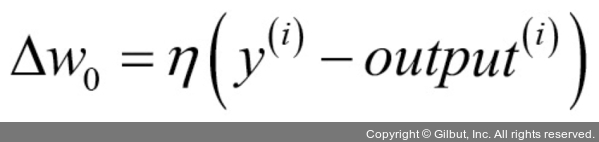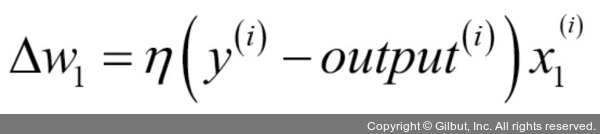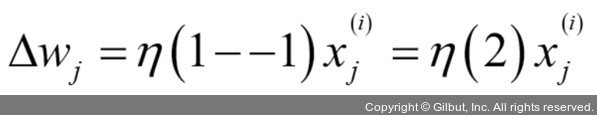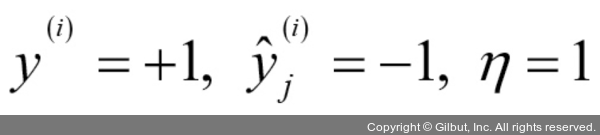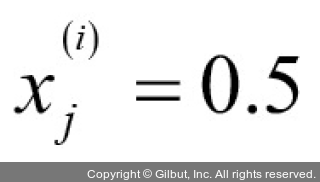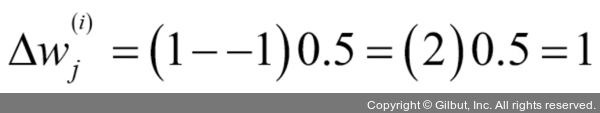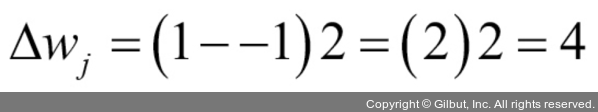2.1 인공 뉴런: 초기 머신 러닝의 간단한 역사 2.2 파이썬으로 퍼셉트론 학습 알고리즘 구현 2.3 적응형 선형 뉴런과 학습의 수렴 2.4 요약
이 장에서는 분류를 위한 초창기 머신 러닝 알고리즘인 퍼셉트론과 적응형 선형 뉴런 두 개를 사용합니다. 파이썬으로 단계적으로 퍼셉트론을 구현하고 붓꽃 데이터셋에서 훈련하여 꽃 품종을 분류합니다.
분류를 위한 머신 러닝 알고리즘 개념을 이해하고, 파이썬을 사용한 효율적인 구현 방법을 익히는 데 도움이 될 것입니다. 적응형 선형 뉴런으로는 기본적인 최적화를 설명합니다. 3장에서 사이킷런 머신 러닝 라이브러리에 있는 강력한 분류 모델을 사용하는 기초를 다질 수 있을 것입니다.
이 장에서는 다음 주제를 다룹니다.
머신 러닝 알고리즘을 직관적으로 이해하기
판다스, 넘파이, 맷플롯립으로 데이터를 읽고 처리하고 시각화하기
파이썬으로 선형 분류 알고리즘 구현하기
2.1 인공 뉴런: 초기 머신 러닝의 간단한 역사
퍼셉트론(perceptron)과 이와 관련된 알고리즘을 자세히 설명하기 전에 초창기 머신 러닝을 간단히 둘러보겠습니다. AI를 설계하기 위해 생물학적 뇌가 동작하는 방식을 이해하려는 시도로, 1943년 워런 맥컬록(Warren McCulloch)과 월터 피츠(Walter Pitts)는 처음으로 간소화된 뇌의 뉴런 개념을 발표했습니다.
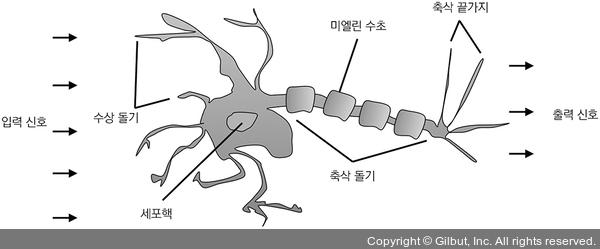
이를맥컬록-피츠(MCP)뉴런이라고 합니다. 뉴런들은 뇌의 신경 세포와 서로 연결되어 있습니다. 그림과 같이 화학적·전기적 신호를 처리하고 전달하는 데 관여합니다.
뇌의 신경 세포
맥컬록과 피츠는 신경 세포를 이진 출력을 내는 간단한 논리 회로로 표현했습니다. 수상 돌기에 여러 신호가 도착하면 세포체에 합쳐집니다. 합쳐진 신호가 특정 임계 값을 넘으면 출력 신호가 생성되고 축삭 돌기를 이용하여 전달됩니다.
몇 년 후에 프랑크 로젠블라트(Frank Rosenblatt)는 MCP 뉴런 모델을 기반으로 퍼셉트론 학습 개념을 처음 발표했습니다. 퍼셉트론 규칙에서 로젠블라트는 자동으로 최적의 가중치를 학습하는 알고리즘을 제안했습니다. 이 가중치는 뉴런의 출력 신호를 낼지 말지를 결정하기 위해 입력 특성에 곱하는 계수입니다. 지도 학습과 분류 개념으로 말하면 이 알고리즘으로 샘플이 한 클래스에 속하는지 아닌지를 예측할 수 있습니다.
McCulloch-Pitts 모델
설명이 어려워서 추가 조사
McCulloch-Pitts 모델에서 사용한 가설은 다음과 같다.
1. 뉴런은 활성화되거나 혹은 활성화되지 않은 2 가지 상태이다. 즉, 뉴런의 활성화는 all-or-none 프로세스이다.
2. 어떤 뉴런을 흥분되게 (excited) 하려면 2개 이상의 고정된 수의 시냅스가 일정한 시간내에 활성화 (activated) 되어야 한다.
3. 신경 시스템에서 유일하게 의미있는 시간지연 (delay) 은 시냅스에서의 지연 (synaptic delay) 이다.
4. 어떠한 억제적인 (inhibitory) 시냅스는 그 시각의 뉴런의 활성화 (activation) 를 절대적으로 방지한다
5. 신경망의 구조는 시간에 따라 변하지 않는다
2.1.1 인공 뉴런의 수학적 정의
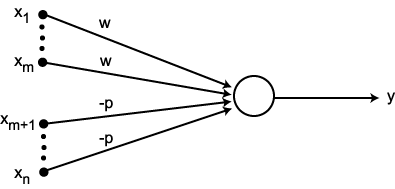
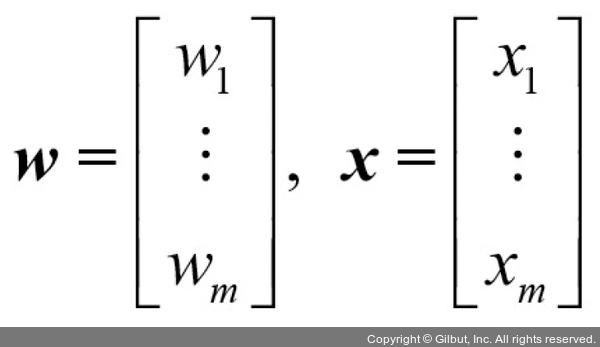
좀 더 형식적으로 말하면인공 뉴런(artificial neuron)아이디어를 두 개의 클래스가 있는 이진 분류(binary classification)작업으로 볼 수 있습니다. 두 클래스는 간단하게 1(양성 클래스)과 -1(음성 클래스)로 나타냅니다. 그다음 입력 값x와 이에 상응하는 가중치 벡터w의 선형 조합으로 결정 함수(ϕ(z))를 정의합니다.
최종 입력(net input)인z는z=w1+x1+…+wmxm입니다.
이제 특정 샘플x(i)의 최종 입력이 사전에 정의된 임계 값θ보다 크면 클래스 1로 예측하고, 그렇지 않으면 클래스 -1로 예측합니다. 퍼셉트론 알고리즘에서 결정 함수ϕ(·)는단위 계단 함수(unit step function)를 변형한 것입니다.
식을 간단하게 만들기 위해 임계 값θ를 식의 왼쪽으로 옮겨wo=-θ고x0=1인 0번째 가중치를 정의합니다. 이렇게 하면z를 좀 더 간단하게 쓸 수 있습니다.
그리고 결정 함수는 다음과 같습니다.
머신 러닝 분야에서는 음수 임계 값 또는 가중치wo=-θ를절편이라고 합니다.
선형대수 표기법
이어지는 절에서는 기초적인 선형대수 표기법을 자주 사용합니다. 예를 들어x와w값을 곱하여 더한 것을 벡터 점곱(dot product)으로 간략히 나타냅니다. 위 첨자T는 열 벡터를 행 벡터로 또는 그 반대로 바꾸는전치(transpose)를 의미합니다.
예를 들어 다음과 같습니다.
또 전치 연산은 행렬에 적용하여 대각 원소를 기준으로 반전시킬 수 있습니다. 예를 들어 다음과 같습니다.
책에서는 아주 기초적인 선형대수만 사용합니다.
그림 2-2는 퍼셉트론 결정 함수로 최종 입력z=wTx가 이진 출력(-1 또는 1)으로 압축되는 방법(왼쪽)과 이를 사용하여 선형 분리가 가능한 두 개의 클래스 사이를 구별하는 방법(오른쪽)을 보여 줍니다.
▲ 그림 2-2 퍼셉트론의 결정 함수와 결정 경계
2.1.2퍼셉트론 학습 규칙
MCP 뉴런과 로젠블라트의 임계 퍼셉트론 모델 이면에 있는 전반적인 아이디어는 뇌의 뉴런 하나가 작동하는 방식을 흉내 내려는 환원주의(reductionism)4접근 방식을 사용한 것입니다. 즉, 출력을 내거나 내지 않는 두 가지 경우만 있습니다. 따라서 로젠블라트의 초기 퍼셉트론 학습 규칙은 매우 간단합니다. 요약하면 다음 과정과 같습니다.
초기 퍼셉트론 학습 규칙 요약
1.가중치를 0 또는 랜덤한 작은 값으로 초기화합니다. 2.각 훈련 샘플x(i)에서 다음 작업을 합니다. a. 출력 값ŷ를 계산합니다. b. 가중치를 업데이트합니다.
여기서 출력 값은 앞서 정의한 단위 계단 함수로 예측한 클래스 레이블입니다. 가중치 벡터w에 있는 개별 가중치wj가 동시에 업데이트되는 것을 다음과 같이 쓸 수 있습니다.5
가중치wj를 업데이트하는 데 사용되는Δwj값은 퍼셉트론 학습 규칙에 따라 계산됩니다.
여기서η는학습률(learning rate)입니다(일반적으로 0.0에서 1.0 사이 정수입니다).
y(i)는i번째 훈련 샘플의진짜 클래스 레이블(true class label)입니다.
ŷ(i)는예측 클래스 레이블(predicted class label)입니다.
가중치 벡터의 모든 가중치를 동시에 업데이트한다는 점이 중요합니다. 즉, 모든 가중치Δwj를 업데이트하기 전에ŷ(i)를 다시 계산하지 않습니다. 구체적으로 2차원 데이터셋에서는 다음과 같이 업데이트됩니다.
파이썬으로 퍼셉트론 규칙을 구현하기 전에 간단한 사고 실험을 하여 이 규칙이 얼마나 멋지고 간단하게 작동하는지 알아보겠습니다. 퍼셉트론이 클래스 레이블을 정확히 예측한 두 경우는 가중치가 변경되지 않고 그대로 유지됩니다.
잘못 예측했을 때는 가중치를 양성 또는 음성 타깃 클래스 방향으로 이동시킵니다.
곱셈 계수를 좀 더 잘 이해하기 위해 다른 예를 살펴보겠습니다.
일 때
이 샘플을 -1로 잘못 분류했다고 가정합니다. 이때 가중치가 1만큼 증가되어 다음 번에 이 샘플을 만났을 때 최종 입력
가 더 큰 양수가 됩니다.
단위 계단 함수의 임계 값보다 커져 샘플이 +1로 분류될 가능성이 높아질 것입니다.
가중치 업데이트는 x 값에 비례합니다. 예를 들어 다른 샘플
를 -1로 잘못 분류했다면 이 샘플을 다음번에 올바르게 분류하기 위해 더 크게 결정 경계를 움직입니다.
퍼셉트론은 두 클래스가 선형적으로 구분되고 학습률이 충분히 작을 때만 수렴이 보장됩니다. 두 클래스를 선형 결정 경계로 나눌 수 없다면 훈련 데이터셋을 반복할 최대 횟수(에포크(epoch))를 지정하고 분류 허용 오차를 지정할 수 있습니다. 그렇지 않으면 퍼셉트론은 가중치 업데이트를 멈추지 않습니다.
다음 절에서 실제로 구현하기 전에 퍼셉트론의 일반적인 개념을 간단한 다이어그램으로 요약해 보죠.
▲ 그림 2-4 퍼셉트론 알고리즘
그림 2-4는 퍼셉트론이 샘플x를 입력으로 받아 가중치w를 연결하여 최종 입력을 계산하는 방법을 보여 줍니다. 그다음 최종 입력은 임계 함수로 전달되어 샘플의 예측 클래스 레이블인 -1 또는 +1의 이진 출력을 만듭니다. 학습 단계에서 이 출력을 사용하여 예측 오차를 계산하고 가중치를 업데이트합니다.
2.2 파이썬으로 퍼셉트론 학습 알고리즘 구현
이전 절에서 로젠블라트의 퍼셉트론 규칙이 어떻게 작동하는지 배웠습니다. 이제 파이썬으로 구현해 봅시다. 그다음 1장에서 소개한 붓꽃 데이터셋에 적용해 보겠습니다.
2.2.1 객체 지향 퍼셉트론 API
객체 지향 방식을 사용하여 퍼셉트론 인터페이스를 가진 파이썬 클래스를 정의하겠습니다.Perceptron객체를 초기화한 후fit메서드로 데이터에서 학습하고, 별도의predict메서드로 예측을 만듭니다. 관례에 따라 객체의 초기화 과정에서 생성하지 않고 다른 메서드를 호출하여 만든 속성은 밑줄(_)을 추가합니다. 예를 들어self.w_와 같습니다.
이 퍼셉트론 구현을 사용하여 학습률eta와 에포크 횟수(훈련 데이터를 반복하는 횟수)n_iter로 새로운Perceptron객체를 초기화합니다.fit메서드에서self.w_가중치를 벡터R(^m+1)로 초기화합니다.
여기서m은 데이터셋에 있는 차원(특성) 개수입니다. 벡터의 첫 번째 원소인 절편을 위해 1을 더했습니다. 즉, 이 벡터의 첫 번째 원소self.w_[0]는 앞서 언급한 절편입니다.
이 벡터는rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])을 사용하여 표준 편차가 0.01인 정규 분포에서 뽑은 랜덤한 작은 수를 담고 있습니다. 여기서rgen은 넘파이 난수(random number)생성기로 사용자가 지정한 랜덤 시드(seed)로 이전과 동일한 결과를 재현할 수 있습니다.
가중치를 0으로 초기화하지 않는 이유는 가중치가 0이 아니어야 학습률η(eta)가 분류 결과에 영향을 주기 때문입니다. 가중치가 0으로 초기화되어 있다면 학습률 파라미터eta는 가중치 벡터의 방향이 아니라 크기에만 영향을 미칩니다. 혹시 삼각법을 알고 있다면 벡터v1=[1 2 3]이 있을 때v1과 벡터v2=0.5×v1 사이 각은 다음 코드에서 보듯이 정확히 0이 됨을 알 수 있습니다.
np.arccos함수는 역코사인 삼각 함수고np.linalg.norm은 벡터 길이를 계산하는 함수입니다. (균등 분포가 아니라 정규 분포를 사용하고 표준 편차 0.01을 선택한 것에는 특별한 이유가 없습니다. 앞서 언급한 것처럼 벡터의 모든 원소가 0이 되는 것을 피하기 위해 랜덤한 작은 값을 얻기만 하면 됩니다.)
Note
1차원 배열의 넘파이 인덱싱(indexing)은 대괄호([])를 사용하는 파이썬 리스트와 비슷하게 작동합니다. 2차원 배열에서 첫 번째 인덱스는 행 번호고, 두 번째 인덱스는 열 번호를 나타냅니다. 예를 들어X[2, 3]이라고 쓰면 2차원 배열X의 세 번째 행과 네 번째 열을 선택합니다.
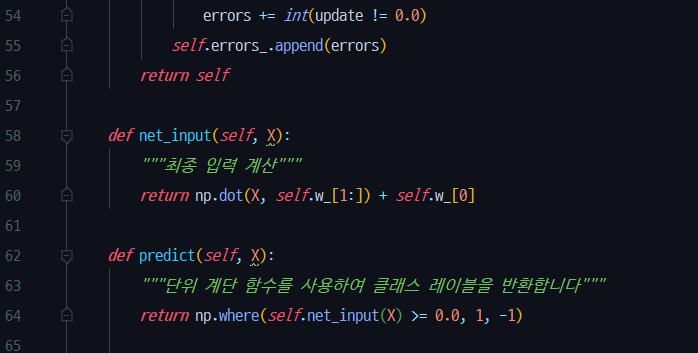
fit메서드는 가중치를 초기화한 후 훈련 세트에 있는 모든 개개의 샘플을 반복 순회하면서 이전 절에서 설명한 퍼셉트론 학습 규칙에 따라 가중치를 업데이트합니다. 클래스 레이블은predict메서드에서 예측합니다.fit메서드에서 가중치를 업데이트하기 위해predict메서드를 호출하여 클래스 레이블에 대한 예측을 얻습니다.predict메서드는 모델이 학습되고 난 후 새로운 데이터의 클래스 레이블을 예측하는 데도 사용할 수 있습니다. 에포크마다self.errors_리스트에 잘못 분류된 횟수를 기록합니다. 나중에 훈련하는 동안 얼마나 퍼셉트론을 잘 수행했는지 분석할 수 있습니다.net_input메서드에서 사용한np.dot함수는 벡터 점곱wTx를 계산합니다.
a.dot(b)나np.dot(a, b)9처럼 넘파이를 사용하여 배열a와b사이의 벡터 점곱을 계산하는 대신 파이썬만 사용하여sum([i * j for i, j in zip(a, b)])처럼 계산할 수도 있습니다.10순수한 파이썬의for반복문 대신 넘파이를 사용하는 이점은 산술 연산을 벡터화하는 것입니다.벡터화(vectorization)는 원소별 산술 연산이 자동으로 배열의 모든 원소에 적용된다는 것을 의미합니다. 한 번에 원소 하나씩 연산을 차례로 수행하는 것이 아니라 하나의 산술 연산을 배열에 대한 연속적인 명령으로 구성하면SIMD(Single Instruction, Multiple Data)를 지원하는 최신 CPU 구조의 장점을 잘 활용할 수 있습니다. 넘파이는 C 또는 포트란으로 쓴BLAS(Basic Linear Algebra Subprograms)와LAPACK(Linear Algebra PACKage) 같은 고도로 최적화된 선형대수 라이브러리를 사용합니다. 넘파이를 사용하면 벡터와 행렬의 점곱 같은 기초적인 선형대수학을 사용하여 간결하고 직관적으로 코드를 작성할 수 있습니다.
2.2.2 붓꽃 데이터셋에서 퍼셉트론 훈련
앞서 만든 퍼셉트론 구현을 테스트하기 위해 붓꽃 데이터셋에서Setosa와Versicolor두 개의 클래스만 사용합니다. 퍼셉트론 규칙이 2차원에 국한된 것은 아니지만 시각화를 하려고 꽃받침 길이와 꽃잎 길이만 고려합니다. 두 개의 꽃 Setosa와 Versicolor만 사용하여 예제를 만들지만 퍼셉트론 알고리즘은 다중 클래스 분류로 확장할 수 있습니다. 예를 들어일대다(One-versus-All, OvA)전략을 사용합니다.
Note
이따금OvR(One-versus-Rest)이라고도 하는OvA기법을 사용하면 이진 분류기를 다중 클래스 문제에 적용할 수 있습니다. OvA를 사용할 때 클래스마다 하나의 분류기를 훈련합니다. 각 클래스는 양성 클래스로 취급되고 다른 클래스의 샘플은 모두 음성 클래스로 생각합니다. 새로운 데이터 샘플을 분류할 때는 클래스 레이블의 개수와 같은n개의 분류기를 사용합니다. 신뢰도가 가장 높은 클래스 레이블을 샘플에 할당합니다. 퍼셉트론은 OvA를 사용하여 최종 입력의 절댓값이 가장 큰 클래스를 레이블로 선택합니다.
먼저pandas라이브러리를 사용하여 UCI 머신 러닝 저장소에서 붓꽃 데이터셋을DataFrame객체로 직접 로드(load)하겠습니다. 데이터가 제대로 로드되었는지 확인하기 위해tail메서드로 마지막 다섯 줄을 출력해 봅니다.
그다음 50개의Iris-setosa와 50개의Iris-versicolor꽃에 해당하는 처음 100개의 클래스 레이블을 추출합니다.12클래스 레이블을 두 개의 정수 클래스1(versicolor)과-1(setosa)로 바꾼 후 벡터y에 저장합니다. 판다스DataFrame의values메서드는 넘파이 배열을 반환합니다.
비슷하게 100개의 훈련 샘플에서 첫 번째 특성 열(꽃받침 길이)과 세 번째 특성 열(꽃잎 길이)을 추출하여 특성 행렬X에 저장합니다. 2차원 산점도(scatter plot)로 시각화해 봅시다.
이 산점도는 붓꽃 데이터셋에 있는 샘플들이 꽃받침 길이와 꽃잎 길이 두 개의 특성 축을 따라 분포된 형태를 보여 줍니다. 이런 2차원 부분 공간에서는 선형 결정 경계로 Setosa와 Versicolor 꽃을 구분하기 충분할 것 같습니다. 퍼셉트론 같은 선형 분류기가 이 데이터셋의 꽃을 완벽하게 분류할 것입니다.
이제 붓꽃 데이터셋에서 추출한 일부 데이터에서 퍼셉트론 알고리즘을 훈련해 보죠. 에포크 대비 잘못 분류된 오차를 그래프로 그려서, 알고리즘이 수렴하여 두 붓꽃 클래스를 구분하는 결정 경계를 찾는지 확인하겠습니다.
그림 2-7에서 볼 수 있듯이 퍼셉트론은 여섯 번째 에포크 이후에 수렴했고 훈련 샘플을 완벽하게 분류했습니다. 간단한 함수를 만들어 2차원 데이터셋의 결정 경계를 시각화해 보겠습니다.
먼저colors와markers를 정의하고ListedColormap을 사용하여colors리스트에서 컬러맵을 만듭니다. 두 특성의 최솟값과 최댓값을 찾고 이 벡터로 넘파이meshgrid함수로 그리드(grid)배열xx1과xx2쌍을 만듭니다.14두 특성의 차원에서 퍼셉트론 분류기를 훈련했기 때문에 그리드 배열을 펼치고 훈련 데이터와 같은 개수의 열이 되도록 행렬을 만듭니다.15predict메서드로 그리드 각 포인트에 대응하는 클래스 레이블Z를 예측합니다.
클래스 레이블Z를xx1,xx2같은 차원의 그리드로 크기를 변경한 후 맷플롯립의contourf함수로 등고선 그래프를 그립니다. 그리드 배열에 대해 예측한 클래스를 각기 다른 색깔로 매핑하여 결정 영역을 나타냅니다.